La traduction automatique : entre idéal, progrès et complexité
Catégorie(s) : L'expertise linguistique
Dans le deuxième article de notre dossier sur la linguistique et la traduction, nous vous proposons de revenir sur ce qu’est réellement la traduction automatisée, son évolution en lien avec les avancées en matière d’intelligence artificielle et les difficultés de conception d’un modèle universel performant !
Aux origines de la traduction automatique
La traduction automatique (TA), vous en avez forcément entendu parler (notamment si vous avez lu la première partie de notre dossier, « Traduction et linguistique : deux domaines a priori proches mais pourtant bien distincts » 😉 ). Ce terme, aujourd’hui inévitablement lié à l’Intelligence Artificielle, est pourtant apparu bien avant tous les termes « tendances » associés à l’IA. Une des hypothèses scientifiques des années 1950-1960 stipulait que :
« N’importe quel texte dans une langue étrangère n’était qu’un code qui pouvait être réencodé vers une autre langue. »
Cette notion de code peut faire allusion au chiffrement-déchiffrement de l’information dont vous avez pu avoir un aperçu si vous avez regardé le film The Imitation Game, revenant sur la vie d’Alan Turing. Pendant la Deuxième Guerre Mondiale, les Allemands utilisaient une machine de cryptographie, Enigma, pour chiffrer leurs communications. Cette machine leur permettait de transférer et recevoir les messages sans que leur sens ne soit compréhensible par ceux qui les interceptaient. Avant le début de la guerre, des cryptoanalystes polonais travaillaient déjà sur un premier outil de déchiffrement des messages d’Enigma. Cependant, cette activité de décryptage était très lente.
En pleine guerre, le but des chercheurs Alliés était ainsi d’améliorer cette méthode et de concevoir une machine capable de décrypter automatiquement les messages de manière (quasi-)instantanée. Finalement, sous l’impulsion d’Alan Turing et son équipe, cette prouesse est devenue possible. Cette avancée scientifique a joué un rôle majeur quant à la victoire des Alliés.
Un mathématicien qui se mettrait à la traduction, plutôt étrange, non ?
Cette analogie est en tout cas un des premiers exemples significatifs démontrant que la traduction automatique ne repose pas uniquement sur la connaissance des langues mais s’appuie aussi fortement sur les mathématiques et les statistiques.
Les progrès de la traduction automatique : modèles linguistiques puis statistiques
Les véritables tentatives pour créer les premiers systèmes de traduction automatique ont vu le jour dans les années 1950. Malgré la forte ambition des chercheurs, cette technologie va rester pendant longtemps très limitée dans son utilisation. D’une part, les performances des « ordinateurs » de l’époque n’étaient pas au niveau des développements requis en vue de la création de cette technologie. D’autre part, les premières approches reposaient sur des savoirs linguistiques, c’est-à-dire des règles. Ces méthodes étaient très chronophages, exigeantes en ressources mais aussi limitées en matière de qualité des résultats. Dans leur fonctionnement, les modèles de traduction à base de règles n’étaient pas exploitables en dehors d’une tâche et d’un contexte concrets et pour une seule combinaison de langues.
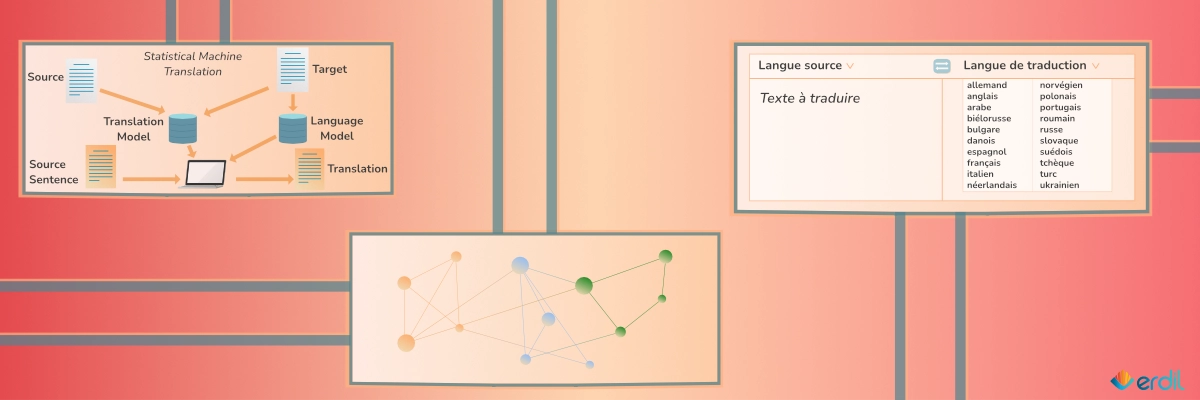
Quelques décennies plus tard, la traduction automatique statistique (Statistical Machine Translation – SMT) remplace les méthodes à base de règles. Pour construire un outil de SMT, on applique des modèles de probabilité statistique sur un grand corpus bilingue pour identifier les correspondances les plus probables entre les mots et les phrases dans les langues respectives. Ces éléments sont extraits sous forme de paramètres qui seront utilisés par la suite pour proposer le mot/la séquence la plus probable (et donc effectuer la traduction). Cette approche de traduction était plus rapide, flexible et pouvait être appliquée à un large éventail de langues et de domaines car on ne s’appuyait pas seulement sur des connaissances linguistiques.
Malgré un tel progrès, cette approche pouvait aussi produire des traductions imprécises voire incohérentes. Ceci était souvent le cas pour des phrases complexes ou des langues ayant peu de caractéristiques en commun. Le deuxième désavantage est que ce modèle reposait sur l’acquisition de grands volumes de données dans les deux langues.
L’impact de l’Intelligence Artificielle sur la traduction automatique
En parallèle à ces avancées, les recherches en Intelligence Artificielle se sont poursuivies, et leurs applications se sont étendues à de nombreux secteurs d’activité. La traduction automatique en a évidemment fait partie. Ces nouvelles approches de traduction automatique reposent notamment sur les réseaux de neurones artificiels, d’où son nom Traduction Automatique Neuronale (Neural Machine Translation – NMT).
Au fil des années, différents modèles neuronaux (RNN, CNN, Transformer…) ont été utilisés au service de l’automatisation de la traduction. À l’heure actuelle, le modèle Transformer produit les meilleurs résultats. Il permet notamment de préserver le sens global d’une séquence, ce qui rend les traductions plus fluides et naturelles.
La magie par l’apprentissage
Lorsque l’on entend parler d’Intelligence Artificielle et surtout de réseaux de neurones, il y a souvent ce côté un peu mystérieux et « magique » : on ne sait pas vraiment ce qu’il y a derrière et on a l’impression que ces technologies peuvent tout faire. En vérité, non : pour l’instant, les modèles d’Intelligence Artificielle apprennent uniquement à partir de ce qu’on leur « montre » et de ce qu’on leur demande d’apprendre.
Imaginez que l’on vous demande de traduire un texte très technique sur les énergies vertes en anglais (sans avoir accès à Internet ou d’autres sources spécialisées). Vous serez obligés de compter uniquement sur vos propres connaissances dans ces deux langues.
Même en étant bilingue, si vous ne maîtrisez pas le vocabulaire du domaine que vous voulez traduire, votre traduction sera moins précise, moins « scientifique ». Vous allez chercher à remplacer les termes techniques par les mots du vocabulaire que vous connaissez, avec plus ou moins de réussite…
Le modèle de NMT généraliste n’aura pas un comportement très différent du vôtre s’il n’a jamais rencontré la terminologie adaptée. En revanche, grâce à son architecture, le modèle de NMT sera plus rapide.
Caractéristiques des modèles de traduction automatiques NMT
Pour ces modèles d’Intelligence Artificielle, les données textuelles ne sont pas utilisées directement dans leur état initial. Afin qu’ils puissent traiter les mots et les phrases de façon plus efficace et rapide, on transpose les données dans l’espace, sous la forme d’un vecteur. Pour simplifier, la distance entre les vecteurs dans cet espace permet de capturer les relations sémantiques.
La plupart des modèles d’apprentissage automatique apprennent de façon itérative : au moment de l’apprentissage, le modèle essaye de proposer des traductions. Par la suite, ces traductions vont être utilisées par le modèle pour ajuster ses futures prédictions. Comme l’humain, il s’appuie sur ses propres erreurs pour s’améliorer.
Ceci ne veut pas dire que le modèle essaye d’apprendre par cœur toutes les données d’entraînement. Un bon modèle est censé apprendre de façon à être capable de généraliser ses connaissances et de s’en servir pour faire des prédictions. La qualité des « connaissances », et par conséquent, les performances des modèles d’IA reposent largement sur les données d’entraînement. Ainsi le choix, la nature et la quantité de celles-ci doivent être bien pensées et adaptées.
Les défauts des modèles généralistes…
Dans le cas de la traduction automatique, les données utilisées doivent être représentatives non seulement de plusieurs langues mais aussi de sujets très diversifiés. Les outils de traduction automatique accessibles au grand public utilisent des données d’entraînement variées mais équilibrées afin de couvrir le plus de sujets possibles et que le modèle soit assez généraliste. Or, dans des contextes bien spécifiques (vocabulaire associé à une technologie ou un secteur d’activité, par exemple), la propension de cet outil à proposer une traduction correcte est beaucoup plus faible.
… et le manque de représentation des corpus spécifiques et données de spécialité
Il n’est pas très compliqué de se procurer des corpus généraux pouvant servir de données d’entraînement pour la traduction automatique tandis que les corpus spécifiques sont sous-représentés et ceux qui sont accessibles ne sont pas toujours assez larges et riches.
Les données de spécialité disponibles dans une des langues concernées peuvent aussi être plus réduites. Cela s’observe notamment par le fait qu’une très large majorité d’articles de recherche sont rédigés en anglais, français voire allemand. Il est donc possible que l’outil de traduction ne trouve pas d’équivalent pour une technologie similaire en slovaque, en turc, etc., puisque le terme qui définit le concept n’existe pas (encore) dans cette langue.
Développer un modèle spécifique : pertinent mais délicat
De la même manière, utiliser uniquement les données spécifiques pour développer un modèle de traduction dédié à un domaine particulier est délicat : si ce modèle pourra introduire plus efficacement la terminologie spécifique au moment de la traduction, il ne sera pas en mesure de généraliser et produire un texte fluide et naturel.
Pour remédier à ce problème, les concepteurs des modèles d’IA peuvent recourir à l’adaptation du modèle au domaine concerné. Cette méthode met à jour un modèle plutôt général avec des données plus spécifiques. Ainsi, si tout se passe bien, ce modèle garde sa capacité généraliste et maximise la précision de la traduction du lexique du domaine. Par contre, une adaptation mal réalisée peut causer un sur-apprentissage (overfitting – le modèle va devenir trop spécifique) ou sous-apprentissage (underfitting – le modèle ne sera pas assez spécifique).
Finalement, pour se rapprocher d’un modèle performant adapté aux besoins, il est nécessaire de fournir initialement :
- beaucoup de données dans les langues respectives
- des données « propres »
- des données adaptées à votre domaine
- des données adaptées à votre objectif
Tous ces facteurs auront un impact significatif sur la qualité de vos traductions !
Dans le prochain article de notre dossier, vous comprendrez, à travers de nombreux exemples parfois très insolites, les tracas que peuvent engendrer les traductions automatiques basées sur des modèles qui ne sont pas complètement aboutis !
Date
05 juin 2023
Auteur



