Anonymisation de zones de texte libre : tour d’horizon (pour le projet DecRIPT)
Catégorie(s) : Sécurité - RGPD
Le projet interrégional DecRIPT, dont ERDIL fait partie, a pour objectif d’améliorer et faciliter la gouvernance et la protection des données, notamment les données personnelles, RGPD oblige. L’un des objectifs du projet est de détecter automatiquement les données sensibles, notamment les données personnelles, au sein de zones de texte libre (en langage naturel), d’identifier leur typologie de données, en vue de les anonymiser en tenant compte de leur type. Dans ce cadre, une étude de l’existant était nécessaire, sujet de ce compte rendu.

Terminologie – Besoin
Le terme anglais Data masking (masquage de données en français) concerne tous les types de données (personnelles et/ou sensibles, telles que des données comptables ou stratégiques), il est plus global et générique que le terme Anonymisation (qui concerne uniquement les données personnelles par définition). Ce dernier est lui-même plus global, générique et plus fort que Pseudonymisation (masquage de données personnelles, mais pas nécessairement de manière irréversible). Enfin, le terme de Tokenisation apparait parfois aussi pour désigner une méthode de masquage «fort» des données particulièrement critiques (telles que : données de santé, bancaire, mot de passe…), sans que cela englobe toutes les typologies de données sensibles ou personnelles. On peut représenter ces différents concepts et leurs relations comme suit :

Le besoin le plus courant (et l’offre) du marché actuel est le masquage de jeux de données de tests, issues de sources de données typées, c’est-à-dire de bases de données relationnelles (= SGBDR) le plus souvent, ou d’autres sources typées : bases NoSQL, fichiers structurés (XML, JSon, CSV…), bases documentaires, etc. Ces jeux de données de tests servent notamment pour la sous-traitance interne et externe (développements et/ou maintenances sous-traités), qui nécessite des jeux de données de tests réalistes, mais anonymisés, pour travailler. C’est pour ces raisons que les termes « Subsetting » et « Test » apparaissent souvent dans les noms des solutions ou dans les documentations de ces solutions.
Le masquage des jeux de données de tests permet de limiter l’accès aux données sensibles, et donc les fuites de données (délibérées ou, plus souvent, accidentelles) car celles-ci proviennent le plus souvent de personnes ayant un accès légitime aux sources de données, contenant des données sensibles (selon les sources, la proportion d’incidents de sécurité d’origine humaine varie de 50 à 80%).
Le besoin, dans le cadre du projet DecRIPT, est différent et spécifique : s’il est aisé d’anonymiser les données personnelles typées, par exemple une colonne « courriel » dans une base de données, ou dans un fichier structuré, il est autrement plus complexe de détecter et anonymiser les données personnelles présentes dans les zones de texte libre (avis client, zone libre de commentaire, etc), et cela sans modifier la signification, la structure, la nature et le sens de ces zones de texte.
Voici quelques exemples (fictifs) présentant différentes méthodes d’anonymisation. À gauche les solutions d’anonymisation «classiques», courantes sur le marché (sur données typées), et à droite celles visées avec le projet DecRIPT (sur zones de texte libre) :

Note : ici, l’anonymisation substitue des valeurs (données personnelles et/ou sensibles) par d’autres valeurs réalistes, crédibles et lisibles « par un humain » (il existe d’autres techniques d’anonymisation, comme l’effacement pur et simple). De plus, si l’on substitue des données par d’autres (fictives) ayant les mêmes types, formats et propriétés que les données originales (tout en empêchant l’opération inverse, dite de « désanonymisation »), cette technique se nomme FPE (Format Preserving Encryption).
Périmètre de cette étude des offres du marché
Les solutions du marché sont toutes plus ou moins capables d’anonymiser des champs typés (= champs contenant une seule donnée et d’un seul type) provenant de sources de données structurées (par exemple des champs Nom, E-mail, Adresse, etc., dans une base de données ou un fichier structuré).
L’objectif de ce tour d’horizon est donc de recenser s’il existe des solutions du marché indiquant proposer une anonymisation de zones de texte libre, c’est-à-dire la capacité à :
- Détecter les différentes catégories de données personnelles dans un texte libre (et les localiser précisément) ;
- Identifier leurs typologies (quel type de donnée personnelle) ;
- Et appliquer, en fonction de chaque type, différentes méthodes et techniques d’anonymisation.
Si l’on peut s’attendre à ce que les éditeurs (commerciaux pour la plupart) communiquent sur ce point lorsque leur solution est capable de cela, il ne faut pas espérer que les éditeurs précisent la façon dont ils détectent ces données personnelles, ou proposent une démonstration en ligne.
À titre d’information, à ce jour (2020), le marché mondial du « data masking » (toutes les variantes, cf. plus haut) est estimé à environ 0,5 milliard de $, et les prévisions vont de 0,8 à plus d’1 milliard de $ pour 2025 selon les sources. On peut supposer que la croissance sera surtout tirée par les réglementations sur les données personnelles (le RGPD en tête, que d’autres pays/régions du monde commencent à suivre, comme le CCPA, ou California Consumer Privacy Act), car les besoins concernant les autres types de données sensibles (non « personnelles ») n’ont pas fondamentalement changé et sont a priori plus « à la marge ». Toutefois la sécurité des données, face à l’explosion des violations et fuites de données personnelles ou sensibles ces dernières années, pourrait être un moteur non négligeable de cette croissance.
Tour d’horizon des solutions du marché
Le point de départ de cette étude a été la liste des solutions du « Magic Quadrant » de Gartner le plus récent trouvé, qui date de décembre 2015 :

Bien que les solutions listées par Gartner (et leurs positions respectives) ont certainement évolué depuis 2015, il est peu probable qu’il y ait de nouveaux acteurs majeurs sur le marché. Cependant, nous avons identifié et listé de nombreux autres acteurs (qui sont de plus en plus nombreux sur le marché), comme nous le montrerons.
Précision 1 : Il n’est pas rare que certains « grands » éditeurs (notamment IBM, HPE, Oracle ou Informatica) proposent une multitude de « solutions de data masking », ce sont généralement des variantes ou des « repackaging » du même logiciel. Ils proposent et déclinent des solutions (par besoin) et non des logiciels (par technologie), dans l’optique évidente d’en vendre plus, car si un client a plusieurs besoins, il se verra proposer plusieurs solutions.
Exemples de découpage : un éditeur pourra décliner le même logiciel (avec de légères variantes tout de même) :
- Pour faire du « subsetting » (extraction de jeux de données de tests anonymisés), de l’anonymisation à la source (in situ), de l’anonymisation de fichiers structurés, etc. ;
- Et/ou selon le métier du client (santé, bancaire, transport, etc) ;
- Et/ou par types métier et/ou techniques des sources données à anonymiser (CRM, ERP, Oracle database, MySQL, Microsoft SQLServer, Cloud de stockage, fichiers structurés, etc) ;
- Et/ou par volume de données à traiter (licence au volume, ce qui est assez courant).
Précision 2 : Les informations présentées ci-dessous s’appuient sur les déclarations des éditeurs (sites web et documents officiels) à la date de l’étude (mars 2020), leur véracité ne peut être vérifiée (les éditeurs ne proposent généralement pas de démos en ligne ou librement téléchargeables). La règle (évidente) pour répondre aux critères du comparatif est la suivante : si l’éditeur ne déclare pas explicitement que sa solution réalise une fonction particulière (en l’occurrence le masquage dans des zones de texte libre), c’est qu’elle n’est pas supportée. De plus, il faut garder à l’esprit qu’il y a parfois un écart important entre le discours commercial et la réalité.
Légende :
| En bleu : il s’agit de 19 solutions non listées dans le « Magic Quadrant » de Gartner en 2015. Celles de Gartner (16 solutions) sont en noir. |
| En violet (colonne sur fond jaune) les solutions indiquant anonymiser des zones de texte libre. |
| N/c = Non communiqué |
| S/o = Sans objet |
Ce tableau liste 35 solutions du marché (dont quelques-unes ont disparu ou ont été rachetées par leur concurrent), classées par ordre alphanumérique croissant sur le nom de l’éditeur, puis sur le nom de la solution, en indiquant les principales sources d’information (url) :
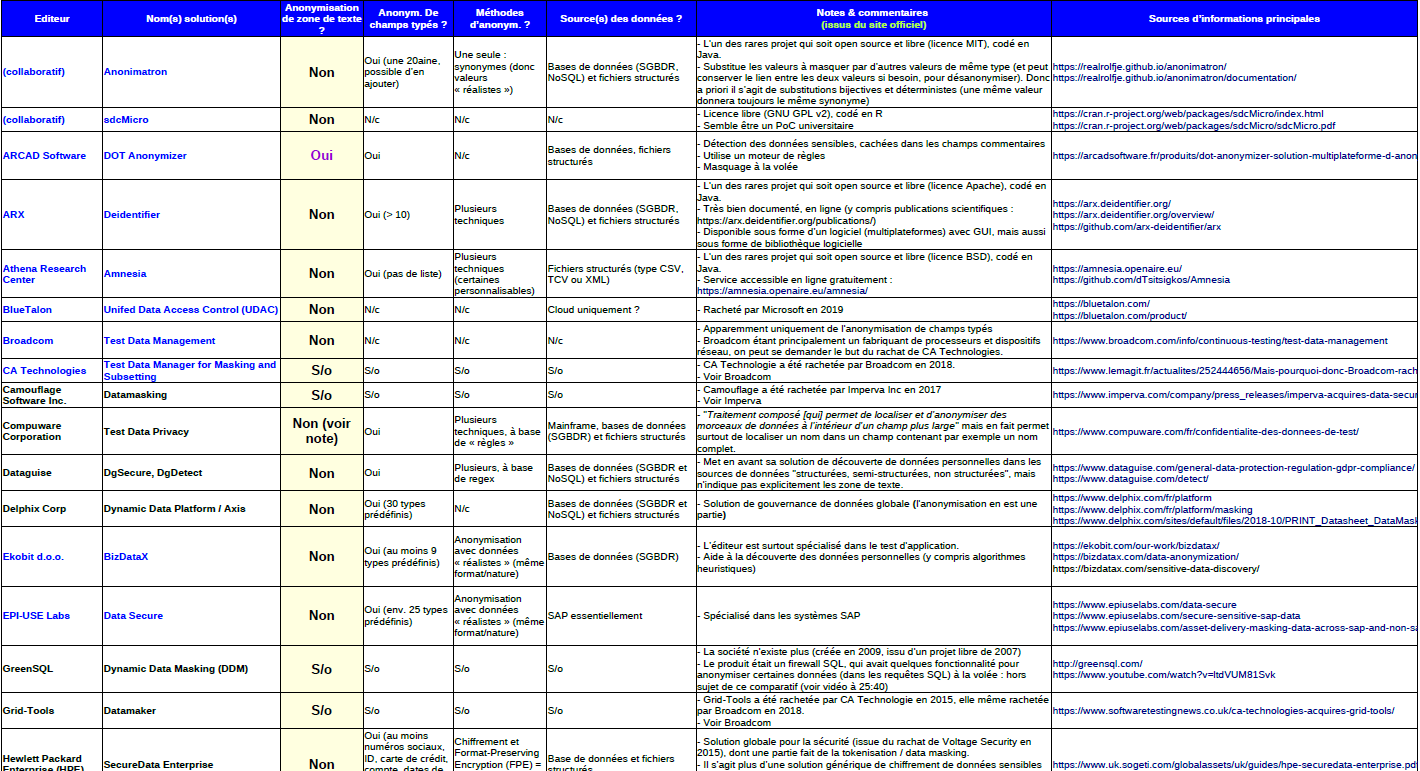
Dans la colonne sur fond jaune, on voit que seules trois solutions (sur 35)indiquent anonymiser des zones de texte libre et aucune ne fait partie du « Magic Quadrant » de Gartner.
La seule qui a pu être testée et vérifiée (gratuite, même si non libre) est « NLM-Scruber », testée avec des textes en anglais, elle n’a pas été convaincante. En effet, elle ne détecte pas tous les patronymes, ni les âges, ni des numéros de sécurité sociale, ni des noms courants de maladies, etc., alors même que c’est une solution d’anonymisation destinée au secteur médical.
En guise de conclusion, ce tour d’horizon du marché montre que l’anonymisation de zone de texte libre est loin d’avoir une réponse courante, mûre et industrielle, et que même les leaders du marché ne semblent pas encore avoir de solution concrète et efficace à cette problématique. Cela constitue tout l’intérêt de notre projet de recherche DecRIPT.
Liste des partenaires du projet DecRIPT :
Date
02 décembre 2020
Auteur